 Newbie
25 posts
Newbie
25 posts
The blackboard made training efficient but not effective.
We need to make learning a personalized Journey with the use of learning chucks or micro learning. We rarely look at the real world; instead we recognize something we have chunked and leave it at that. So chunking is natural habit and we do it all the time, this way establishing a library of chunked knowledge (“practice”) ready to apply. In Pedagogy these chucks are directed from the trainer to the learner. In Andragogy (Knowles) the learner is facilitated in selecting the correct chunks, that stimulate competency development. Heutagogy (Hase & Kenyon) is self-determined learning where the learner selects and creates curated chunks that lead to the development of capabilities, establishing double loop learning. Paragogy (Corneli & Danoff) is peer to peer learning where learning chucks are exchanged between learners.
To actually create learning, you need a couple other things in addition to your micro learning. Too often, what’s proposed is to take a big course, break it down into small chunks, and stream them out. That sounds good, but it’s missing the nuances of learning. It takes repeated practice, over time, interleaved with other retrieval, and revisited.


The leading strategy maps to the perfect blend:
- During socialization use paragogy with the expertise from the unconscious competent (SME), to guide the conscious incompetent.
- During externalization and combination, you will need to strengthen the tacit-tacit learning, using pedagogy and andragogy.
- The newly conscious competent keeps learning using heutagogy and paragogy.
As an elearning specialist you must find the ideal distribution system for your chuncks that will support these strategies:
- Pedagagy are best accommodated with Learning Programs
- Andragogy needs limited guidance via the use of Dynamic Learning Paths
- Heutagogy can be provided by a well Curated Learning Catalog using AI suggestions
- Paragogy benefits from persistent communication platform
This also alligns with the “Understanding Macro vs. Micro Learning” from Josh Bersin
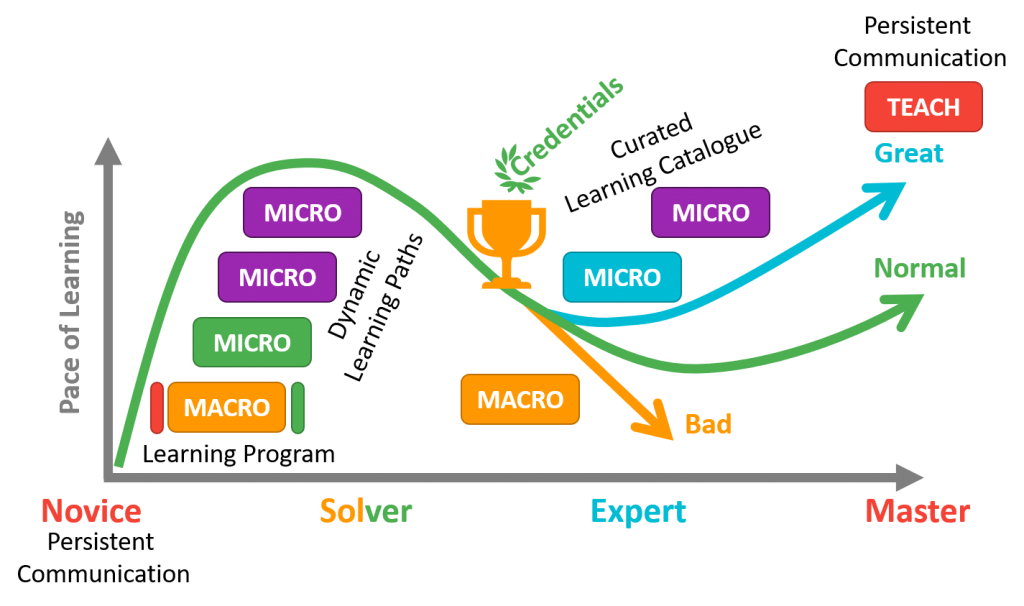
These also match flow and motivation

Adobe Captivate Prime is a good place to start distributing your chunks.
We need to make learning a personalized Journey with the use of learning chucks or micro learning. We rarely look at the real world; instead we recognize something we have chunked and leave it at that. So chunking is natural habit and we do it all the time, this way establishing a library of chunked knowledge (“practice”) ready to apply. In Pedagogy these chucks are directed from the trainer to the learner. In Andragogy (Knowles) the learner is facilitated in selecting the correct chunks, that stimulate competency development. Heutagogy (Hase & Kenyon) is self-determined learning where the learner selects and creates curated chunks that lead to the development of capabilities, establishing double loop learning. Paragogy (Corneli & Danoff) is peer to peer learning where learning chucks are exchanged between learners.
To actually create learning, you need a couple other things in addition to your micro learning. Too often, what’s proposed is to take a big course, break it down into small chunks, and stream them out. That sounds good, but it’s missing the nuances of learning. It takes repeated practice, over time, interleaved with other retrieval, and revisited.
The leading strategy maps to the perfect blend:
- During socialization use paragogy with the expertise from the unconscious competent (SME), to guide the conscious incompetent.
- During externalization and combination, you will need to strengthen the tacit-tacit learning, using pedagogy and andragogy.
- The newly conscious competent keeps learning using heutagogy and paragogy.
As an elearning specialist you must find the ideal distribution system for your chuncks that will support these strategies:
- Pedagagy are best accommodated with Learning Programs
- Andragogy needs limited guidance via the use of Dynamic Learning Paths
- Heutagogy can be provided by a well Curated Learning Catalog using AI suggestions
- Paragogy benefits from persistent communication platform
This also alligns with the “Understanding Macro vs. Micro Learning” from Josh Bersin
These also match flow and motivation
Adobe Captivate Prime is a good place to start distributing your chunks.




You must be logged in to post a comment.
- Most Recent
- Most Relevant
